Multi-Modal Emotion Recognition in Conversational AI

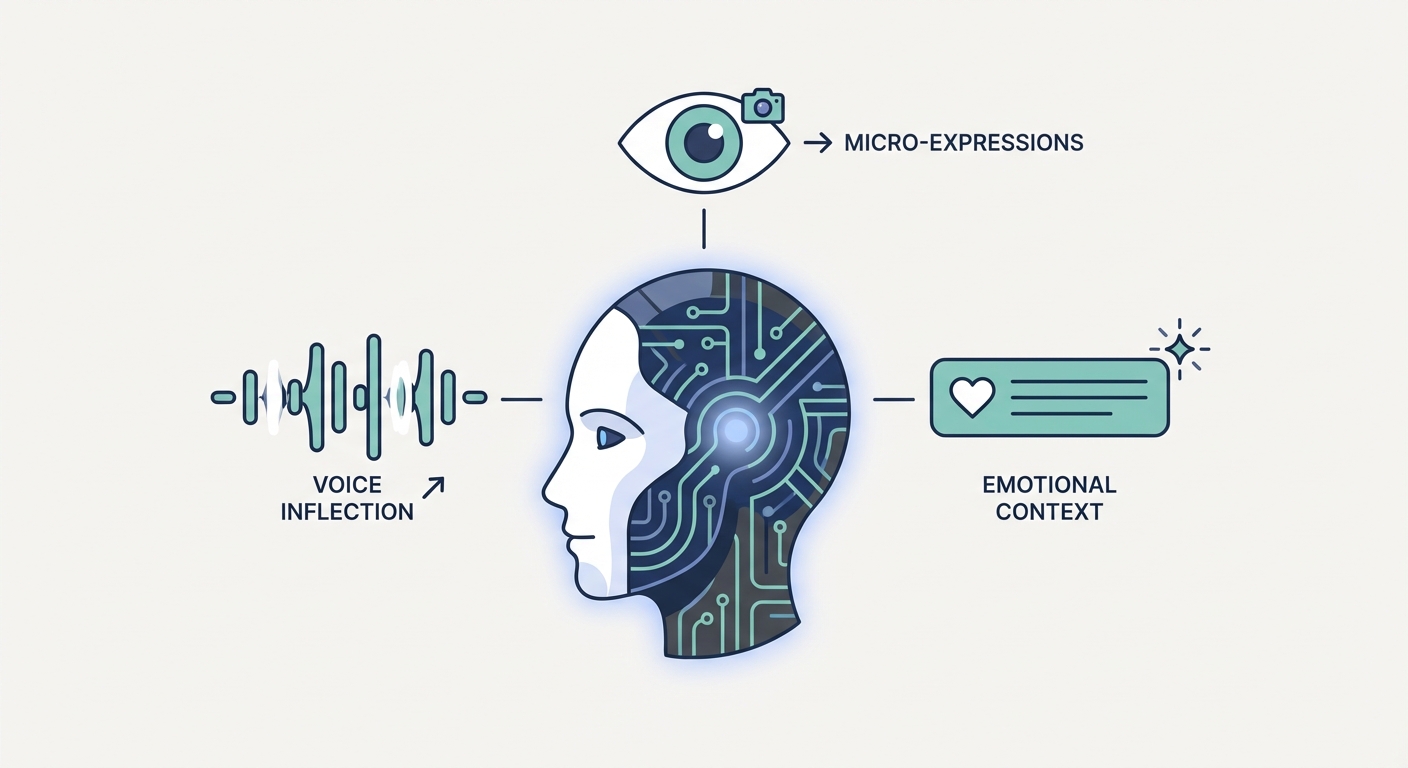
TL;DR
- Text-only LLMs fail to detect sarcasm, frustration, and nuanced human intent.
- MER integrates text, audio, and visual data to understand emotional context.
- Multi-modal models bridge the satisfaction gap in automated customer support.
- Moving beyond semantics allows AI to truly 'read the room' like humans.
If your conversational AI is stuck with only text, it’s not just limited—it’s effectively deaf and blind.
Large Language Models (LLMs) have gotten scarily good at syntax and fact-checking. But ask one to handle a frustrated customer who’s trying to be polite, and the magic falls apart. These models are fundamentally stunted because they ignore the "how" of human communication. By skipping over prosody, facial micro-expressions, and body language, they miss the signals that actually define intent.
Multi-modal emotion recognition (MER) is the bridge. It’s the shift from processing cold, hard tokens to actually "reading the room." It transforms an AI from a glorified script-reader into something that can actually participate in a conversation.
What is Multi-Modal Emotion Recognition (MER)?
At its heart, MER is just stitching together different data streams to figure out how a human is actually feeling. Traditional sentiment analysis is a one-dimensional game; it looks at a string of text and spits out a polarity score. It’s boring, and it’s usually wrong.
MER relies on the "Three Pillars" of human communication:
- Text (Semantics): The literal words spoken.
- Audio (Prosody/Pitch): The rhythm, melody, and tone that betray emotion, regardless of the words used.
- Visual (Facial/Gestural Data): The non-verbal "truth-filter"—a furrowed brow, a smirk, or avoidant eye contact.
When you synthesize these, you stop guessing what a user means and start understanding how they feel. It’s the difference between hearing someone and listening to them.
Why is Text-Only Analysis Failing Your Users?
The "Satisfaction Gap" killing enterprise AI right now is a failure of perspective. If a customer says, "I’m fine," a text-only LLM sees a positive confirmation. A human—or a multi-modal model—sees a potential churn risk. Sarcasm, irritation, and genuine delight aren’t found in the dictionary. They’re found in the delivery.
When your model ignores vocal pitch or visual context, it ignores the truth of the interaction. This is why standard LLM-based support agents often feel "robotic" and dismissive—they are literally incapable of reading the room.
How Does the Architecture of Emotion Work in 2026?
Building this stuff isn't just about feeding one big prompt into a black box. It’s about complex pipeline orchestration. We’re synchronizing time-aligned data streams in real-time.
How do we extract features from disparate data streams?
The heavy lifting happens in parallel. For text, we use transformer-based encoders to capture deep semantic meaning. For audio, we use models like wav2vec or specialized prosody encoders to isolate the variance in pitch, tempo, and energy. For vision, we use Convolutional Neural Networks (CNNs) or Vision Transformers (ViTs) to track facial landmarks. The real trick? Getting these models to speak the same mathematical "language" before they hit the fusion layer.
What is the difference between Early and Late Fusion?
This is the big design choice. Early Fusion mashes raw features together at the input level. It lets the model learn cross-modal correlations from the ground up. It’s computationally expensive, yes, but it catches the nuances you’d otherwise miss. Late Fusion is the lazy cousin: you train independent models for each stream and combine their final predictions (like a weighted average). It’s easier to build and debug, but you lose the granular, "in-the-moment" connections that happen when audio and text are fused at the feature level.
How do Graph Neural Networks (GNNs) model conversation history?
Isolated utterances are just snapshots. Conversations are movies. GNNs allow us to track emotional shifts across a long-form dialogue by mapping the conversation as a series of nodes (utterances) and edges (relational dependencies). By mapping the history, a GNN can identify that a user’s slowly increasing agitation is a reaction to a specific policy mentioned three turns ago. It provides the context necessary for a truly adaptive response.
Why Does Your Model Fail in Real-World Production?
Moving from a clean lab environment to a noisy, real-world production system is where most AI projects go to die. The "Generalization Gap" is brutal. Background subway noise, bad lighting on a Zoom call, and people talking over each other can tank your accuracy by 40% or more. According to the latest academic consensus, if you aren't training your models to handle environmental noise, you're effectively building a toy, not a tool.
Also, "Human-in-the-Loop" validation isn't optional. As models become more autonomous, they might misinterpret cultural nuances. You need a feedback loop where humans refine the model’s understanding of "frustration" versus "passionate debate" to keep the system fair and accurate.
How Can Businesses Implement Advanced Emotion AI?
Implementing this tech isn't about throwing away your current stack; it’s about upgrading it. We’re seeing a massive shift toward "prompt learning" for resource-constrained environments. It lets developers leverage pre-trained multi-modal encoders without needing a supercomputer for every single inference call. Recent breakthroughs in text-audio fusion mean we can achieve high-fidelity emotion recognition with much lower latency than we thought possible a year ago.
If you’re struggling to bridge the gap between a standard LLM and a truly aware agent, the architecture is everything. At Kveeky, we focus on the bespoke integration needed to turn these abstract architectures into production-ready pipelines. Whether you’re starting from scratch or retrofitting an existing agent, our real-world AI integration case studies prove that the ROI on empathetic AI shows up where it counts: in reduced churn and higher customer satisfaction.
What Does the 2026 Enterprise Landscape Look Like?
We are finished with the "AI experiment" phase. We’re in the era of "CX ROI." With the market for emotion-aware systems projected to hit $1.4B by 2034, companies that drag their feet will soon be seen as legacy providers. As highlighted in recent Voice AI trends for 2026, the expectation for machines to understand human nuance is no longer a luxury—it’s the baseline. The future belongs to the systems that don't just hear the words, but listen to the person behind them.
Frequently Asked Questions
Why do AI models struggle to recognize sarcasm using only text?
Sarcasm is basically a cross-modal contradiction. The literal text says one thing, but the prosody (pitch, tempo, and volume) and facial expressions say the opposite. Without the audio and visual context, the model is missing the "truth-marker" needed to detect irony, so it just takes the statement at face value.
What is the difference between 'Early Fusion' and 'Late Fusion' in emotion AI?
Early Fusion combines raw feature vectors from text, audio, and video before the classification stage. It’s great for learning fine-grained correlations but is computationally heavy. Late Fusion trains individual models for each modality and merges their final predictions. It’s simpler to manage but often misses the subtle, synchronized cues that define complex emotions.
How do you handle privacy concerns when processing video/audio for emotion recognition?
Privacy is managed through edge-processing and strict data anonymization. By processing audio and video features locally on the device—or using anonymized feature embeddings rather than raw media—we ensure that sensitive biometric data is never stored or transmitted. This keeps things compliant with modern privacy frameworks while maintaining the model’s ability to "see" and "hear" the user.
Is real-time multi-modal emotion recognition possible on edge devices?
Yes, thanks to model quantization and advancements in prompt learning. By compressing heavy encoders and focusing on lightweight feature fusion, it’s now possible to achieve sub-100ms latency for emotion detection—even on consumer-grade hardware. Real-time, empathetic interaction isn't a pipe dream anymore; it’s here.



