Google Launches Gemini 3.1 Flash with Advanced TTS Capabilities for Enterprise Voice Infrastructure

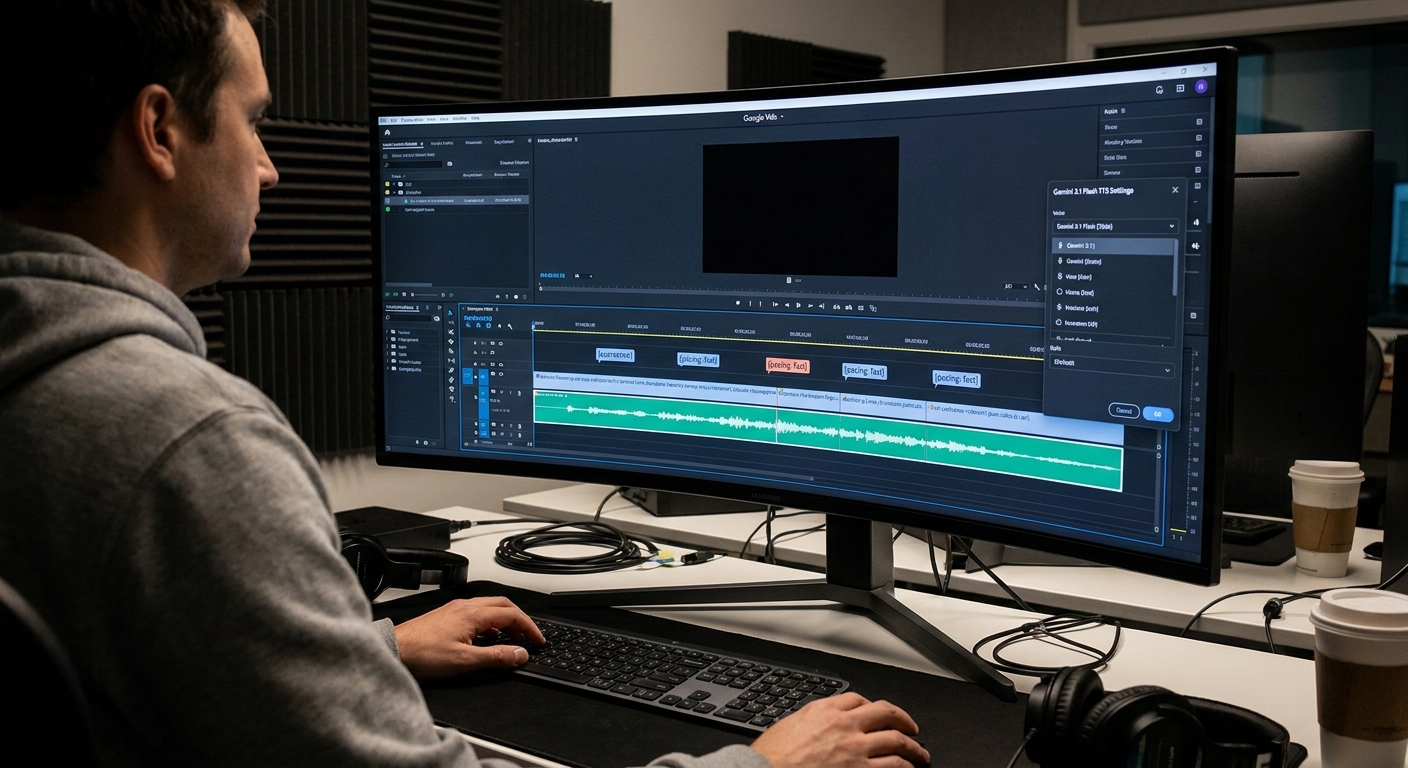
Google just pulled the curtain back on Gemini 3.1 Flash TTS, a specialized model built to bring high-fidelity, human-like audio to the enterprise world. It’s a bold move, effectively pushing the company’s generative voice portfolio into new territory. If you want to kick the tires, it’s already sitting in public preview over at Google AI Studio and Vertex AI.
Announced on April 26, 2026, the real hook here isn’t just the voice quality—it’s the control. Developers can now manipulate speech output using a library of over 200 natural language audio tags. You want a whisper? A sudden burst of excitement? A faster, more urgent pace? You just embed tags like [whispers], [fast], or [excitement] directly into your text. It’s a massive step away from the flat, metallic drone we’ve all come to associate with "AI voices" and a giant leap toward something that actually sounds like a person speaking in a professional setting. By leaning on the Gemini 3.1 Flash architecture, Google is betting they can keep latency low while keeping the vocal quality surprisingly high.
Expanded Linguistic and Technical Scope
The sheer scale of this rollout is hard to ignore. We’re talking support for over 70 languages and regional variants right out of the gate. For global enterprises, that’s a game-changer. You need a consistent brand voice that sounds as natural in Tokyo as it does in London? Google has provided 30 prebuilt base voices to serve as your foundation, making it much easier to maintain a cohesive brand identity across borders.
We’re already seeing this in the wild. Google Vids has already baked Gemini 3.1 Flash TTS into its voiceover engine. The result? Much more expressive audio and the addition of 16 new languages to the platform. According to the official announcement, the model is handling complex narrative flows and shifting emotional tones with a level of nuance that was, until recently, pretty rare for automated systems.
Core Features and Implementation Details
The architecture is built for people who need precision. By embedding markers directly into the text strings, you aren't just telling the AI what to say; you're telling it how to feel. It’s a subtle but critical distinction.
Here is the breakdown of what’s currently on the table in the public preview:
- Granular Control: Access to 200+ natural language audio tags for real-time style adjustments.
- Linguistic Breadth: Support for 70+ languages and regional variants, detailed in the official language documentation.
- Voice Variety: A library of 30 unique, prebuilt base voices.
- Security: Mandatory SynthID watermarking to ensure all generated audio is clearly identifiable as AI-synthesized.
| Feature | Specification |
|---|---|
| Model Version | Gemini 3.1 Flash TTS |
| Language Support | 70+ languages |
| Base Voices | 30 unique profiles |
| Control Mechanism | 200+ natural language tags |
| Security Protocol | SynthID watermarking |
Integration and Accessibility
For the engineering teams trying to fit this into existing workflows, Google has kept the integration path relatively straightforward. You can find the implementation guide in the technical documentation. The beauty of the tag-based system is that you don’t need to retrain models or build out a Rube Goldberg machine of audio editing tools. You just drop the tags in, and the model handles the rest.
Then there’s the security angle. Google is leaning hard into SynthID watermarking. By embedding an imperceptible watermark into every audio stream, they’re making it possible to trace AI-generated content—a non-negotiable for most enterprise compliance departments. It’s baked in by default, so you don’t have to worry about flipping the right switches to stay compliant.
While the model is still in public preview, the potential use cases are already stacking up. From automated customer service agents that actually sound empathetic to multimedia production tools like Google Vids, the tech seems ready for prime time. The jump to 16 additional languages in Vids is a solid proof-of-concept for how this scales. As the preview period rolls on, we’ll likely see even tighter latency and even more polished voice profiles. If you’re building out voice infrastructure, it’s worth taking a look at the Cloud documentation to see how these tools might fit into your stack. The era of robotic, one-note AI speech is ending; the era of granular, expressive, and scalable voice infrastructure is officially here.



