Mistral AI Launches Voxtral 4B Open-Weight Model to Advance Low-Latency Multilingual Voice Synthesis


Mistral AI Drops Voxtral 4B: A New Contender in Real-Time Voice Synthesis
Mistral AI just shook up the generative audio space. On March 26, 2026, they rolled out Voxtral 4B—an open-weight text-to-speech model built for speed, emotional range, and enterprise-grade reliability. If you’ve been waiting for a voice model that doesn’t choke on latency or cost a fortune to run, this is the one to watch.
The industry has been hungry for high-fidelity voice tech that isn’t locked behind a proprietary wall. Mistral is betting that by giving developers the keys to the kingdom, they can push voice agents into a new era of responsiveness. You can dig into the specifics via the official Voxtral TTS announcement.
Under the Hood: The Architecture
So, how does it actually work? Voxtral 4B ditches the clunky, slow methods of the past. It uses a hybrid architecture, pairing auto-regressive semantic token generation with flow-matching for acoustic tokens. In plain English? It’s fast. It’s fluid. It sounds like a human, not a robot reading a tax form.
The secret sauce is the "Voxtral Codec," which relies on a hybrid Vector Quantization-Finite Scalar Quantization (VQ-FSQ) scheme. It’s a mouthful, but the result is clean, high-fidelity audio that holds up under pressure. If you’re the type who likes to get lost in the math, the official research paper lays it all out.
Perhaps the most impressive party trick is the zero-shot voice adaptation. Give the model three seconds of audio, and it’s off to the races. It captures the essence of the speaker—the cadence, the tone, the quirks—and can even maintain those characteristics while switching languages. It’s a massive step forward for cross-lingual synthesis.
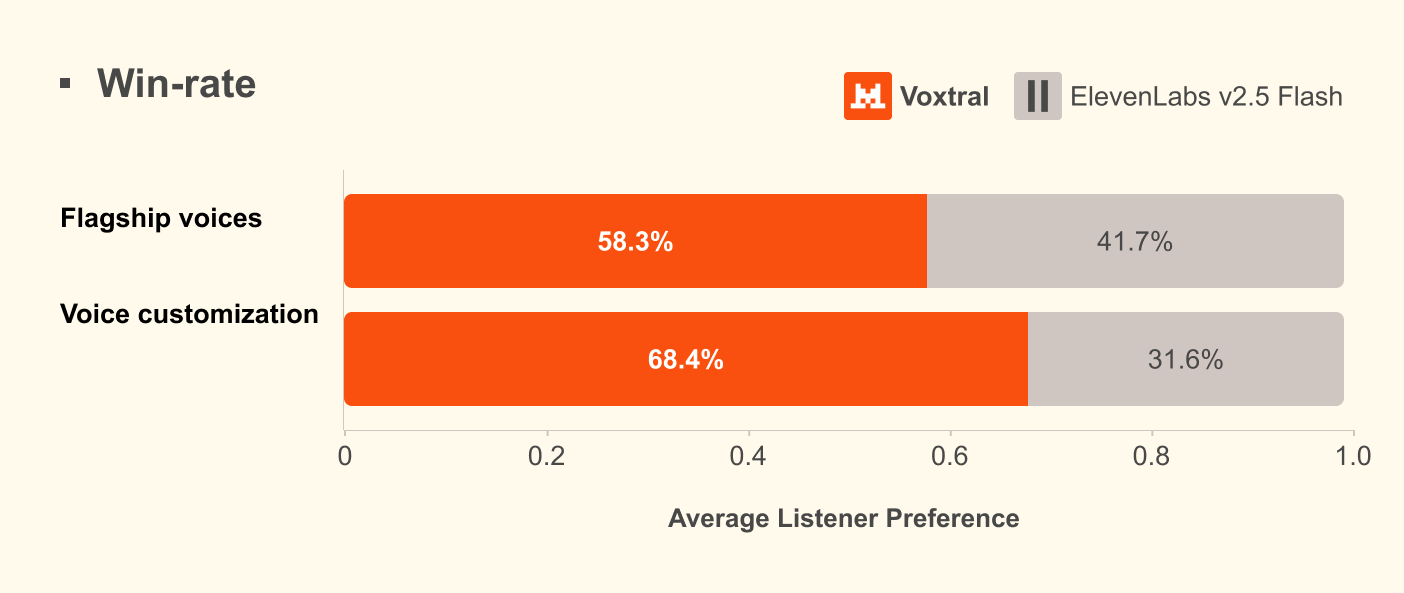
Performance That Actually Matters
Voxtral 4B covers nine languages right out of the gate: English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic. It’s a solid lineup for anyone building global applications.
But does it hold up? The benchmarks suggest it does. In human preference tests, Voxtral 4B reportedly notched a 68.4% win rate over ElevenLabs Flash v2.5. It’s even going toe-to-toe with ElevenLabs v3. For an open-weight model, that’s a hell of a statement.
| Feature | Specification/Capability |
|---|---|
| Model Size | 4 Billion Parameters |
| Supported Languages | 9 (EN, FR, DE, ES, NL, PT, IT, HI, AR) |
| Reference Audio Needed | Minimum 3 seconds |
| Architecture | Auto-regressive + Flow-matching |
| Primary Design Goal | Low-latency, high-speed execution |
Building with Voxtral
Mistral’s decision to go the open-weight route is a direct jab at the "cloud-only" status quo. By letting developers host the model themselves, they’re effectively killing the latency issues that have plagued voice agents for years. You aren't just renting a voice; you’re building an infrastructure.
If you’re ready to start tinkering, the weights are live on the Hugging Face repository. For those who prefer a managed experience, it’s also integrated into the Mistral AI console. Whether you’re building an edge-based assistant or a massive customer service pipeline, the flexibility is there.
The real takeaway here is the focus on speed. We’ve all dealt with those "smart" assistants that pause for three seconds before answering a simple question. It’s jarring, and it ruins the illusion of a conversation. By optimizing the 4B parameter space, Mistral has managed to keep the quality high while keeping the compute requirements sane.
As teams start pushing this into production, the conversation will inevitably shift toward how we balance these massive models with the reality of limited hardware. But for now, Voxtral 4B looks like a genuine leap forward. It’s not just about the tech—it’s about making voice interaction feel, well, human again. Whether this becomes the new gold standard for open-source audio remains to be seen, but the bar has definitely been raised.



