Mistral AI Launches Voxtral 4B Open-Weight Model to Advance Low-Latency Multilingual Voice Synthesis


TL;DR
- Mistral AI releases Voxtral 4B, a powerful, open-weight text-to-speech model.
- Enables private, high-fidelity, multilingual voice synthesis without API dependencies.
- Features 4B parameters, supporting real-time inference on standard consumer hardware.
- Offers zero-shot voice cloning with support for nine major languages.
- Positions Mistral as a direct competitor to proprietary API-based voice providers.
Mistral AI Drops Voxtral 4B: A New Standard for Open-Weight Voice Synthesis
Mistral AI just shook up the audio world. They’ve officially pulled the curtain back on Voxtral TTS, a 4-billion-parameter text-to-speech model that’s lean, mean, and surprisingly expressive. Forget the usual cloud-gated black boxes; Mistral is handing over the weights, letting anyone with the hardware run high-fidelity, multilingual voice synthesis right on their own infrastructure.
It’s a bold move. By decoupling voice generation from the typical API-first model, Mistral is essentially handing enterprises the keys to their own kingdom. No more worrying about data privacy leaks or the recurring nightmare of per-character billing. If you want to scale a voice agent for customer support or sales, you can finally do it without tethering your business to a third-party cloud provider.
Under the Hood: Efficiency Meets Expression
The architecture here is the real story. At 4 billion parameters, Voxtral hits a sweet spot—it’s small enough to run on standard consumer-grade hardware but powerful enough to sound human. We’re talking speeds six times faster than real-time on a basic laptop. That kind of efficiency is a game-changer for edge computing, where every millisecond of latency matters.
But how does it sound? The model handles nine languages—English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic—with impressive linguistic dexterity. The standout feature? Zero-shot voice adaptation. Feed it just three seconds of audio, and it’s off to the races, cloning or adapting a voice profile with uncanny accuracy. It even handles cross-lingual tasks, keeping the cadence and accent of your source audio even when it’s spitting out a different language.
The Competitive Landscape
Let’s be real: this is a direct shot across the bow at ElevenLabs, Deepgram, and OpenAI. Those companies have built empires on proprietary APIs, keeping their models locked behind a digital velvet rope. Mistral’s strategy is the polar opposite. As TechCrunch recently pointed out, this is a play for the enterprise market—a sector that values data sovereignty and brand-specific voice control above almost everything else.
With the earlier arrival of Voxtral Transcribe, Mistral has effectively finished building its own "enterprise-owned" AI stack. You’ve got the ears (transcription) and now the voice (synthesis), both open-weight and ready for deployment. It’s a complete toolkit for anyone tired of being a tenant in someone else’s ecosystem.
| Feature | Specification |
|---|---|
| Model Size | 4 Billion Parameters |
| Language Support | 9 (EN, FR, DE, ES, NL, PT, IT, HI, AR) |
| Latency | 6x faster than real-time (on laptop) |
| Voice Adaptation | Zero-shot (3 seconds reference) |
| Deployment | Local, On-Premise, or Cloud |
Why This Matters for Enterprise
If you’re currently paying through the nose for Mistral’s audio build tools or similar cloud services, the math is simple: local hosting kills the overhead. By bringing the model in-house, you drop the latency that usually plagues network-dependent synthesis and stop the bleeding caused by those "per-minute" usage fees.
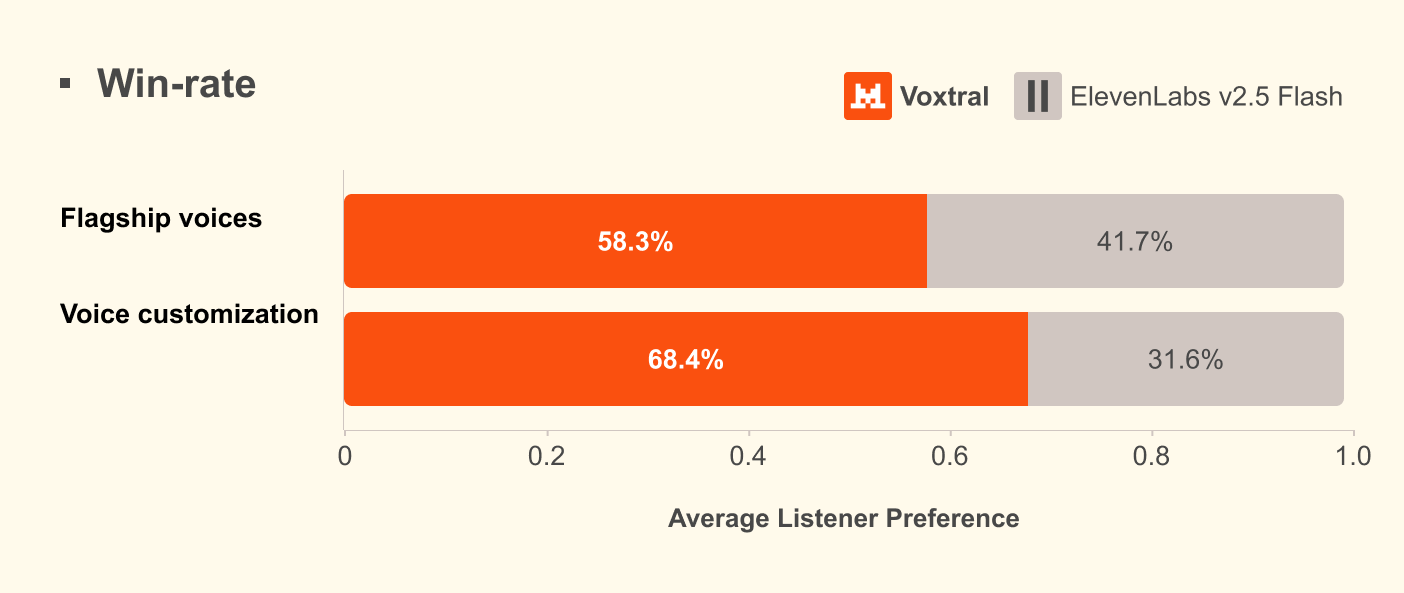
The performance metrics are equally compelling. In internal testing, the model has reportedly edged out ElevenLabs Flash v2.5 in both naturalness and accent adherence. That’s not just a vanity metric—in high-stakes customer engagement, the difference between "robotic" and "human" is the difference between a sale and a hang-up.
For the deep dive into the technical weeds, integration guides, and the licensing fine print, you can check out the official Voxtral TTS announcement.
Mistral AI is clearly playing the long game. Backed by a $13.8 billion valuation following their $2 billion Series C round, they aren’t just releasing models; they’re building a platform. As they weave these tools into their broader Studio platform, the message to developers is clear: you don’t need to be a prisoner of a closed-source ecosystem to build world-class voice agents. You just need the right weights and the freedom to run them. The barriers to entry for low-latency, high-quality voice AI just got a whole lot lower.



